

Overview
[TL;DR] We develop two simple but effective dataset pruning methods for transfer learning covering both supervised and self-supervised settings, and achieve lossless performance on various downstream tasks.
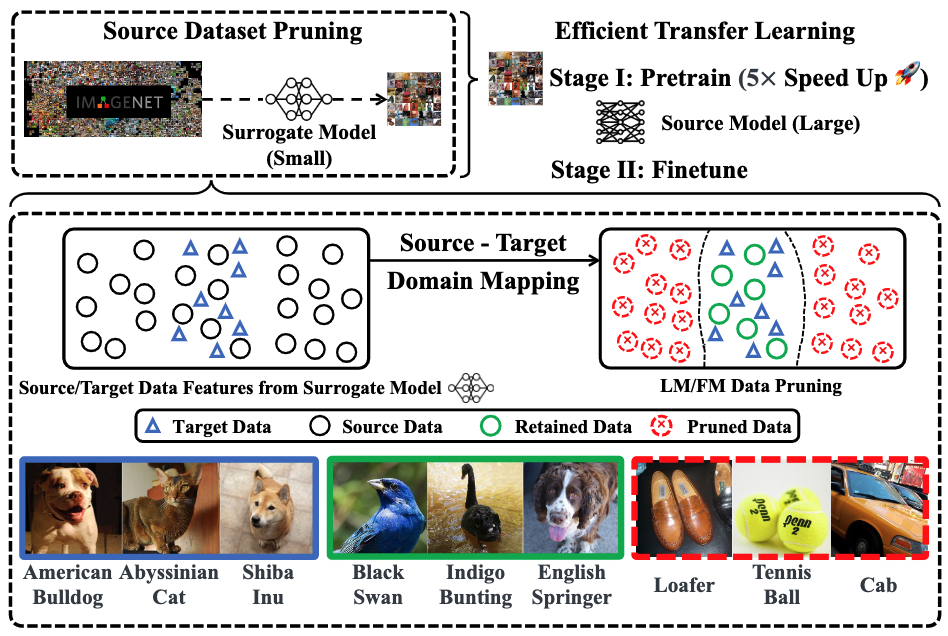
Dataset Pruning for Transfer Learning
Massive data is often considered essential for deep learning applications, but it also incurs significant computational and infrastructural costs. Therefore, dataset pruning has emerged as an effective way to improve data efficiency by identifying and removing redundant training samples without sacrificing performance. In this work, we aim to address the problem of dataset pruning for transfer learning. Ideally, a all-round dataset pruning method for transfer learning should contain the following good properties:
- Lossless performance: pretraining on the pruned source dataset should lead to lossless or even improved performance on the finetuning task.
- High efficiency: the pruning operation itself should be efficient to perform;
- Broad applicability: the proposed method should be applicable to various pretraining settings, such as supervised and unsupervised pretraining;
To our best knowledge, the problem of dataset pruning for transfer learning remains open, as previous studies have primarily addressed dataset pruning and transfer learning as separate problems.
By contrast, we establish a unified viewpoint to integrate DP with transfer learning and find that existing DP methods are not suitable for the transfer learning paradigm. We then propose two new DP methods, label mapping and feature mapping, for supervised and self-supervised pretraining settings respectively, by revisiting the DP problem through the lens of source-target domain mapping. we demonstrate the effectiveness of our approach on numerous transfer learning tasks. We show that source data classes can be pruned by up to 40% ∼ 80% without sacrificing downstream performance, resulting in a significant 2 ∼ 5× speed-up during the pretraining stage.
Motivation and Preliminary Study
Why do we perform dataset pruning on the source (pretraining) dataset?
Do the existing dataset pruning methods work for transfer learning?
Not All Source Classes Are Necessary
Some source data could make a harmful influence in the downstream performance.
Removing specific source classes can improve transfer learning.
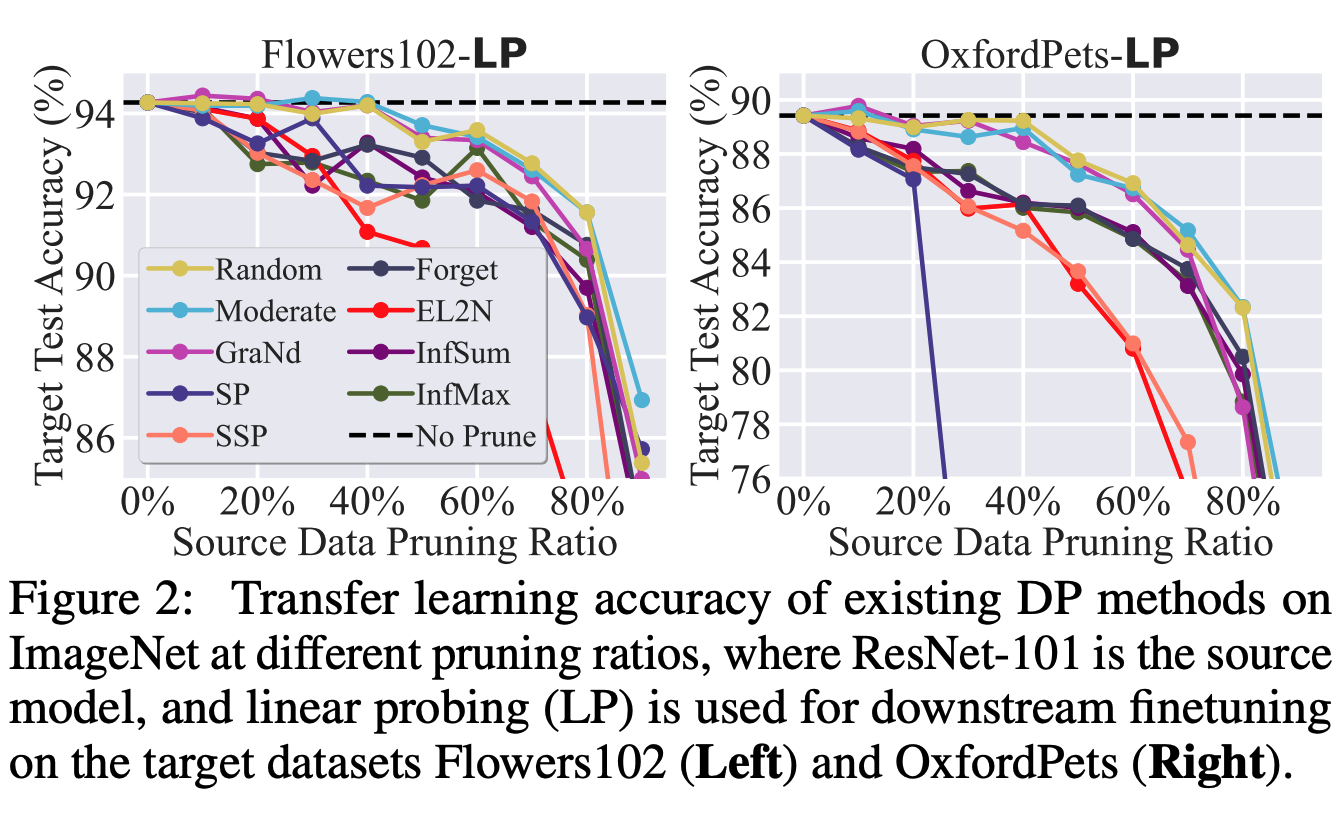
Conventional Dataset Pruning lacks effectiveness on Transfer Learning.
In transfer learning, conventional SOTA dataset pruning methods do NOT yield significant performance improvement over random pruning
It is crucial to develop an efficient and effective DP method specifically tailored for transfer learning.
Dataset Pruning for Transfer Learning
Label Mapping & Feature Mapping
This paper proposes two simple but powerful and efficient methods for supervised and unsupervised pretraining.
Label Mapping for Supervised Pretraining
-
01 Rational behind our design.
Source data similar to downstream data intend to contribute more during the transfer process. How to quantitatively measure the relevance between the source and downstream data becomes a key.
-
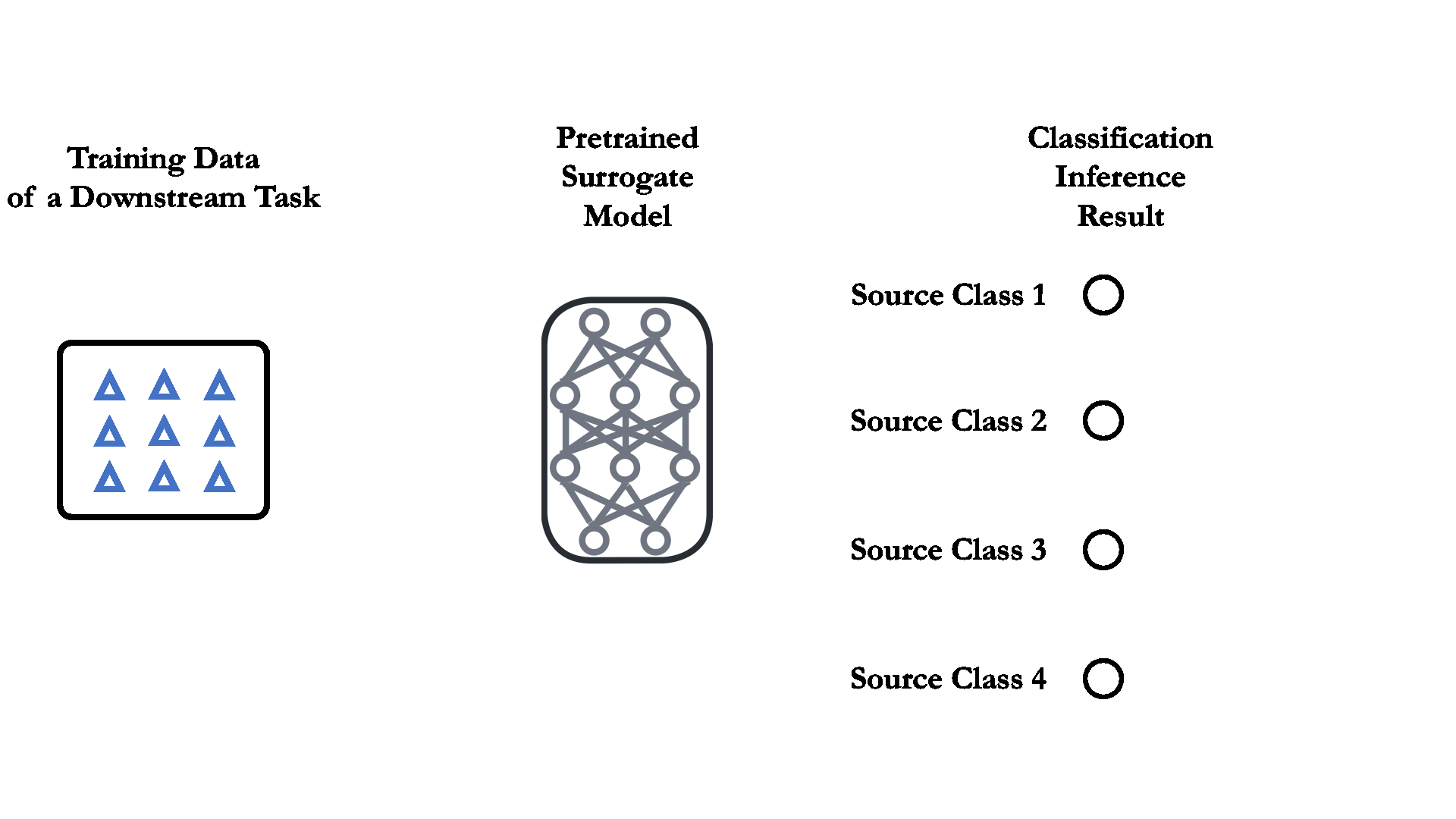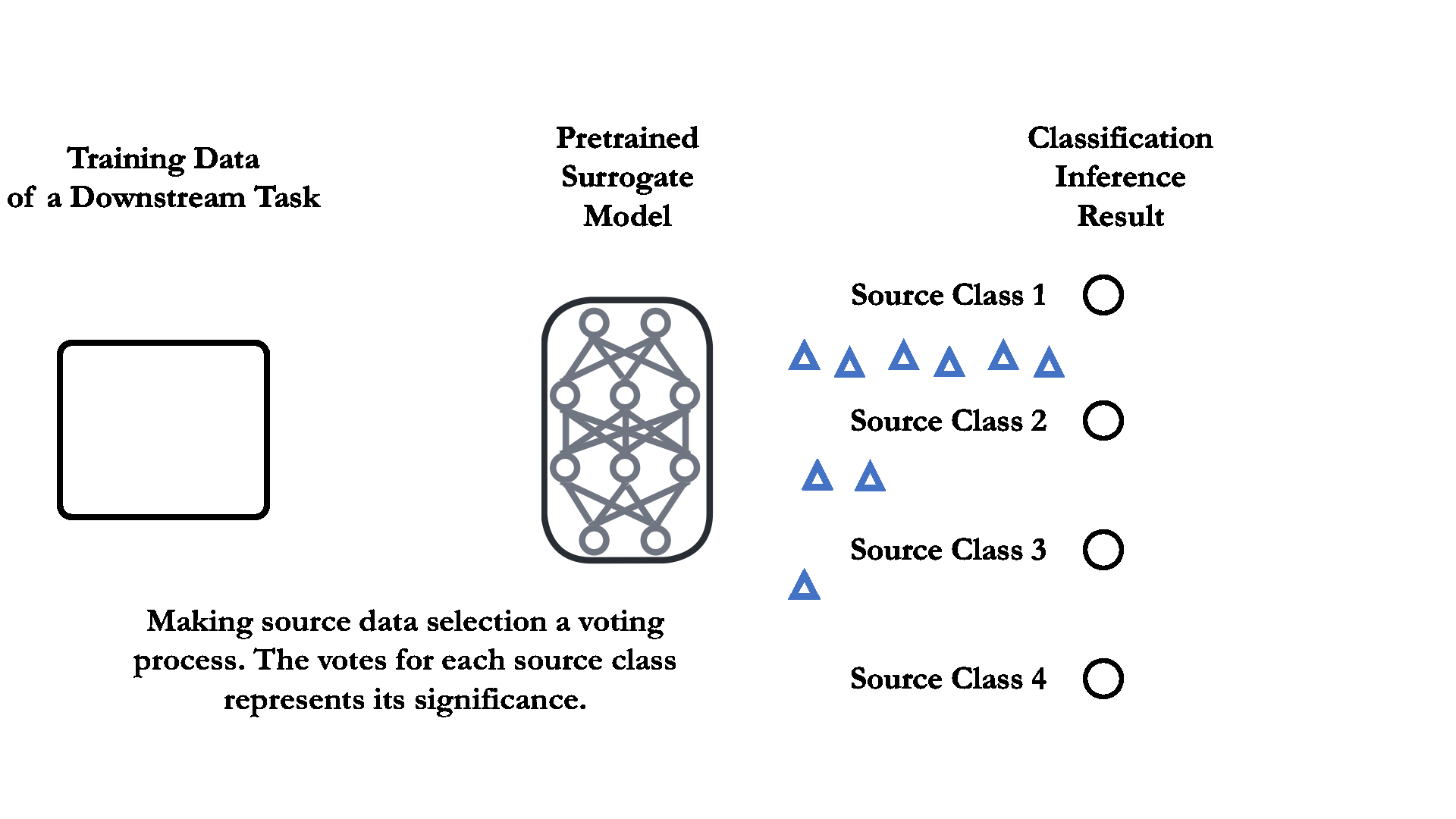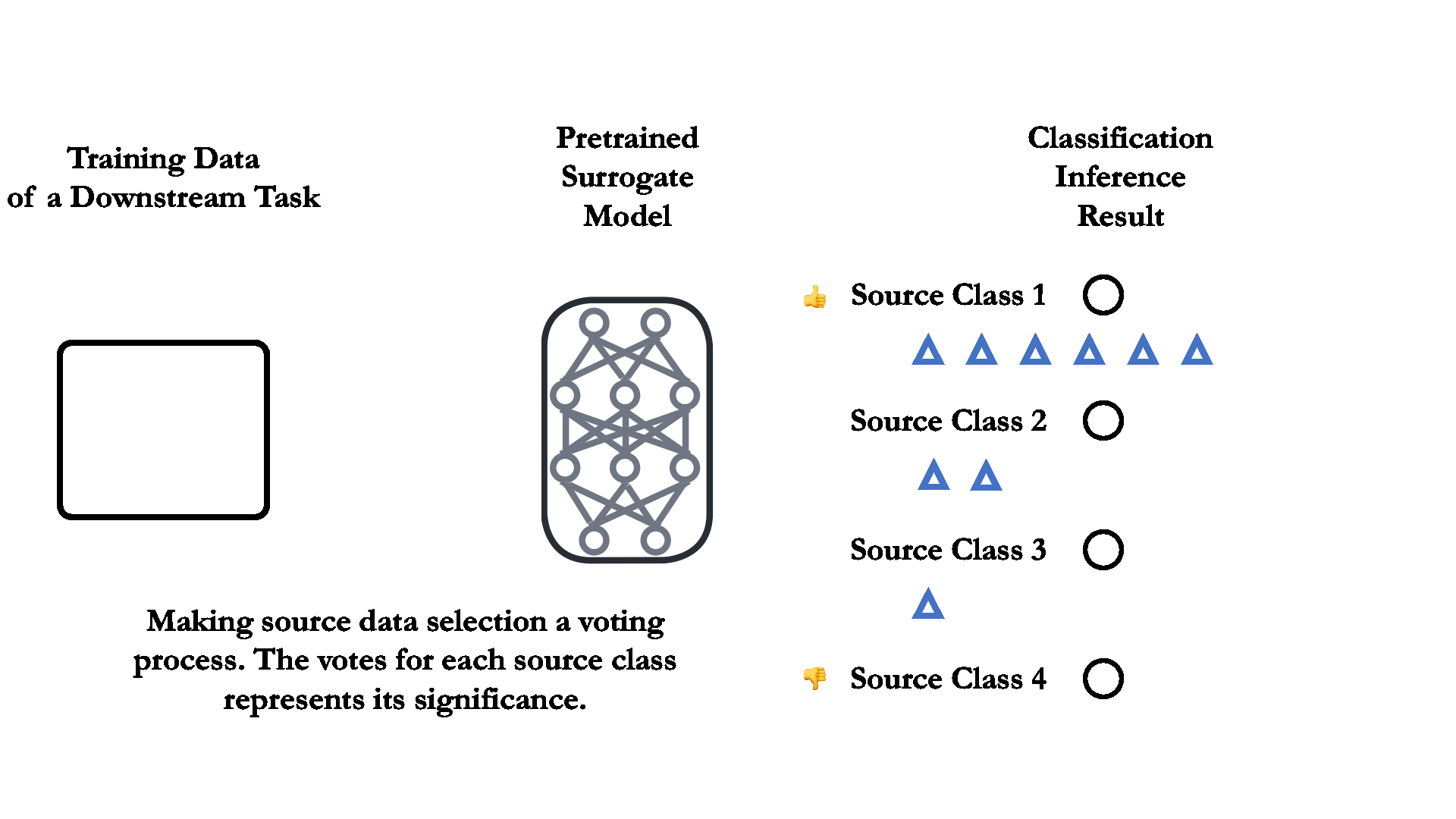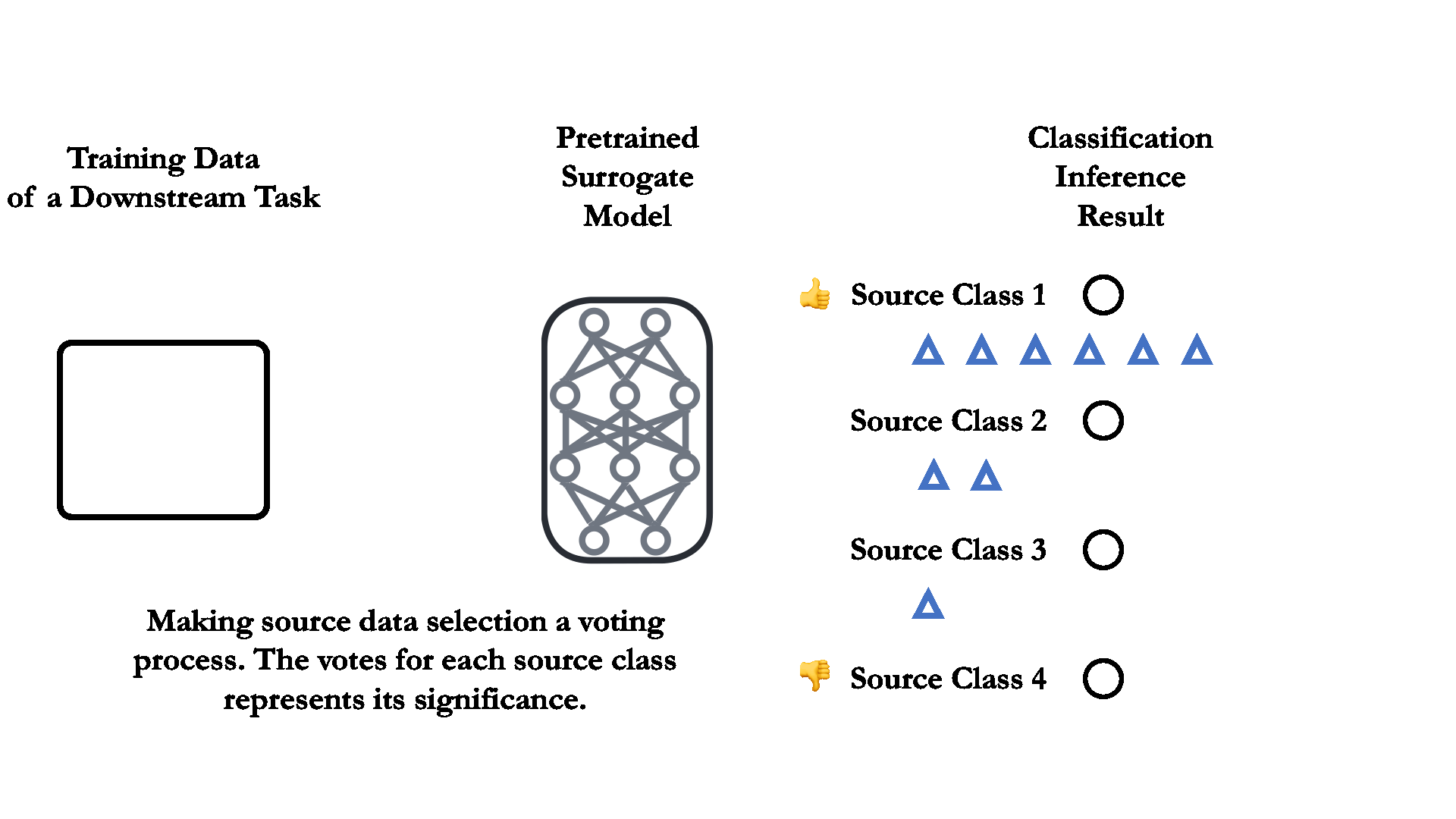
02 Dataset selection as a voting process.
To quantitatively measure the relevance between the source and downstream data, the dataset pruning for transfer learning can be viewed as a “voting” process, each downstream training data can vote for its most similar/relevant source training class.
-
03 Label mapping through a pretrained small surrogate model.
For supervised pretrained classification model, the voting process is as simple as directly feeding the downstream training data into a pretrained surrogate model. The source classes that receives the most downstream training data are considered the most "relevant" one. See the right figure for illustration.
The pretrained surrogate model can be as small as less than 1% the size of the model we aim to train. The superior performance on the source dataset of the surrogate model is also not necessary in the label mapping process.
Feature Mapping for Unsupervised Pretraining
-
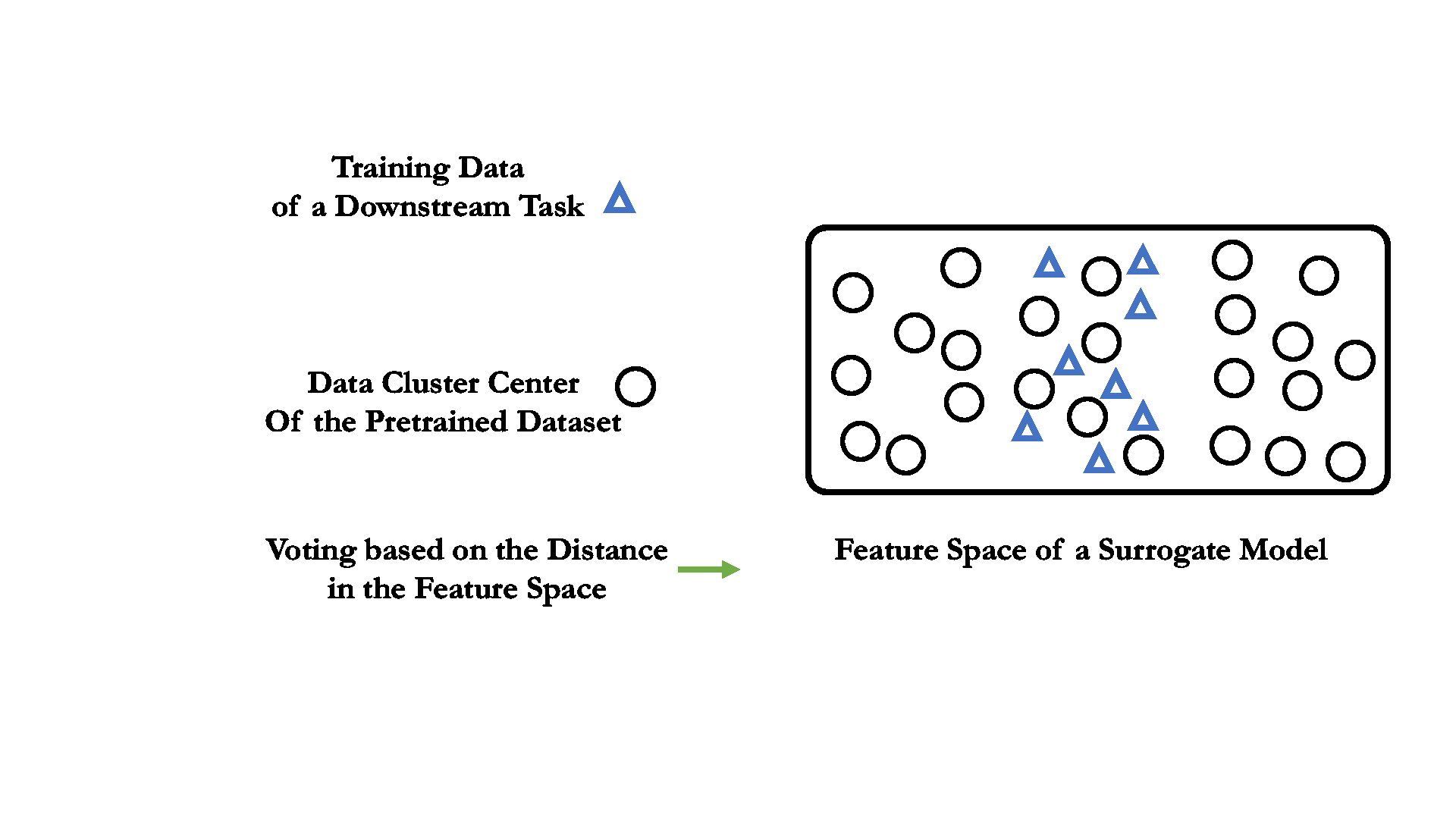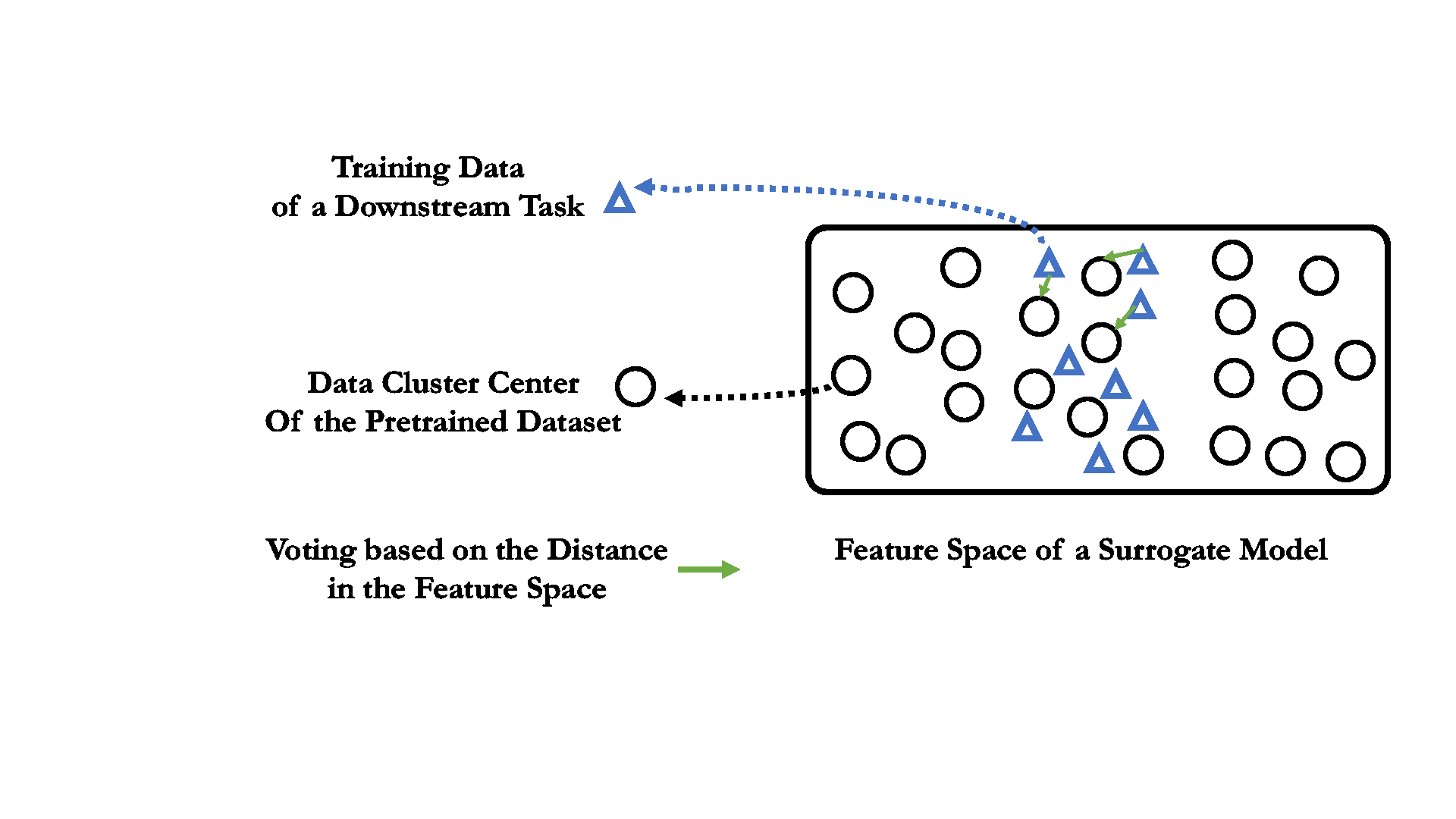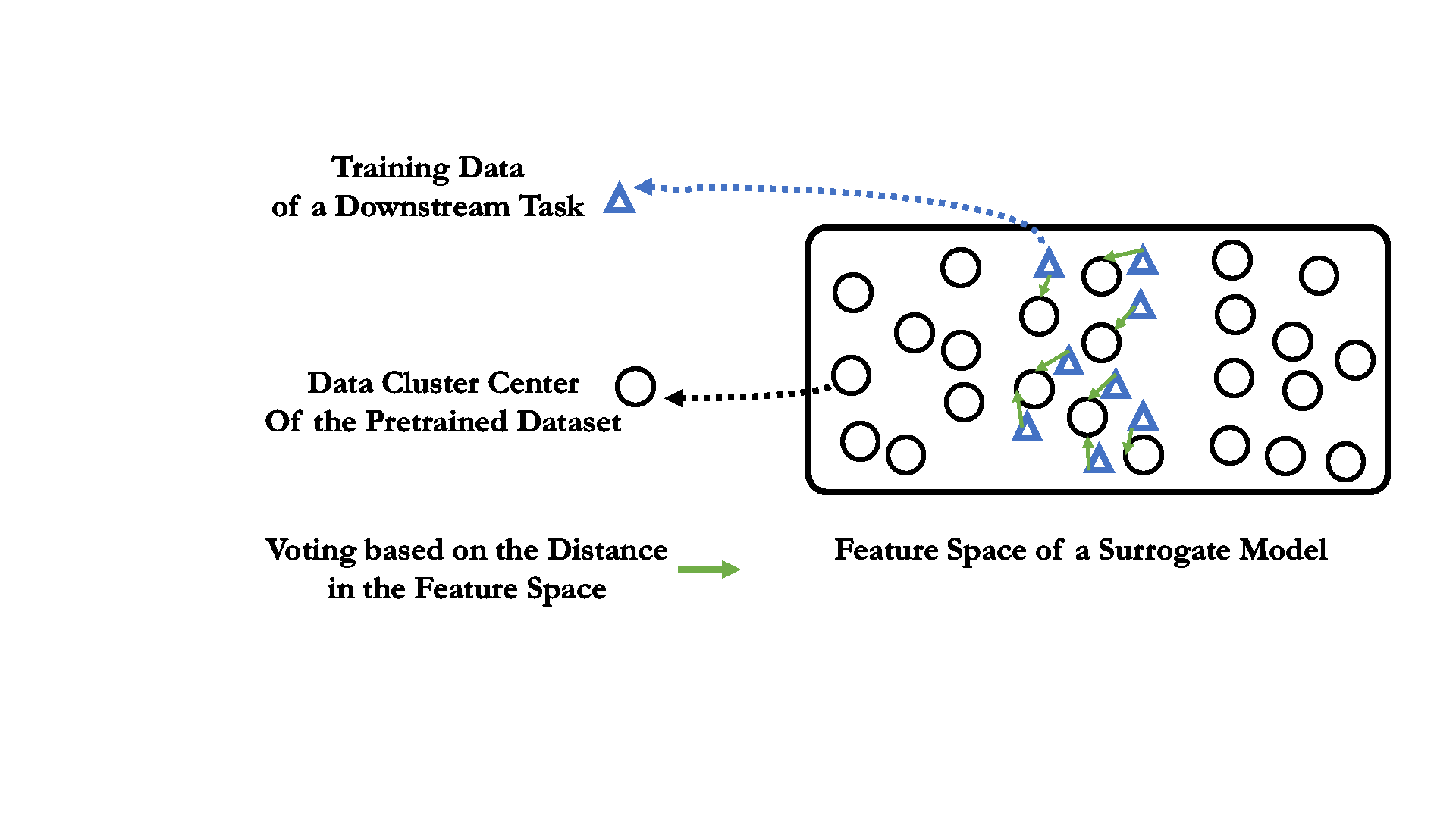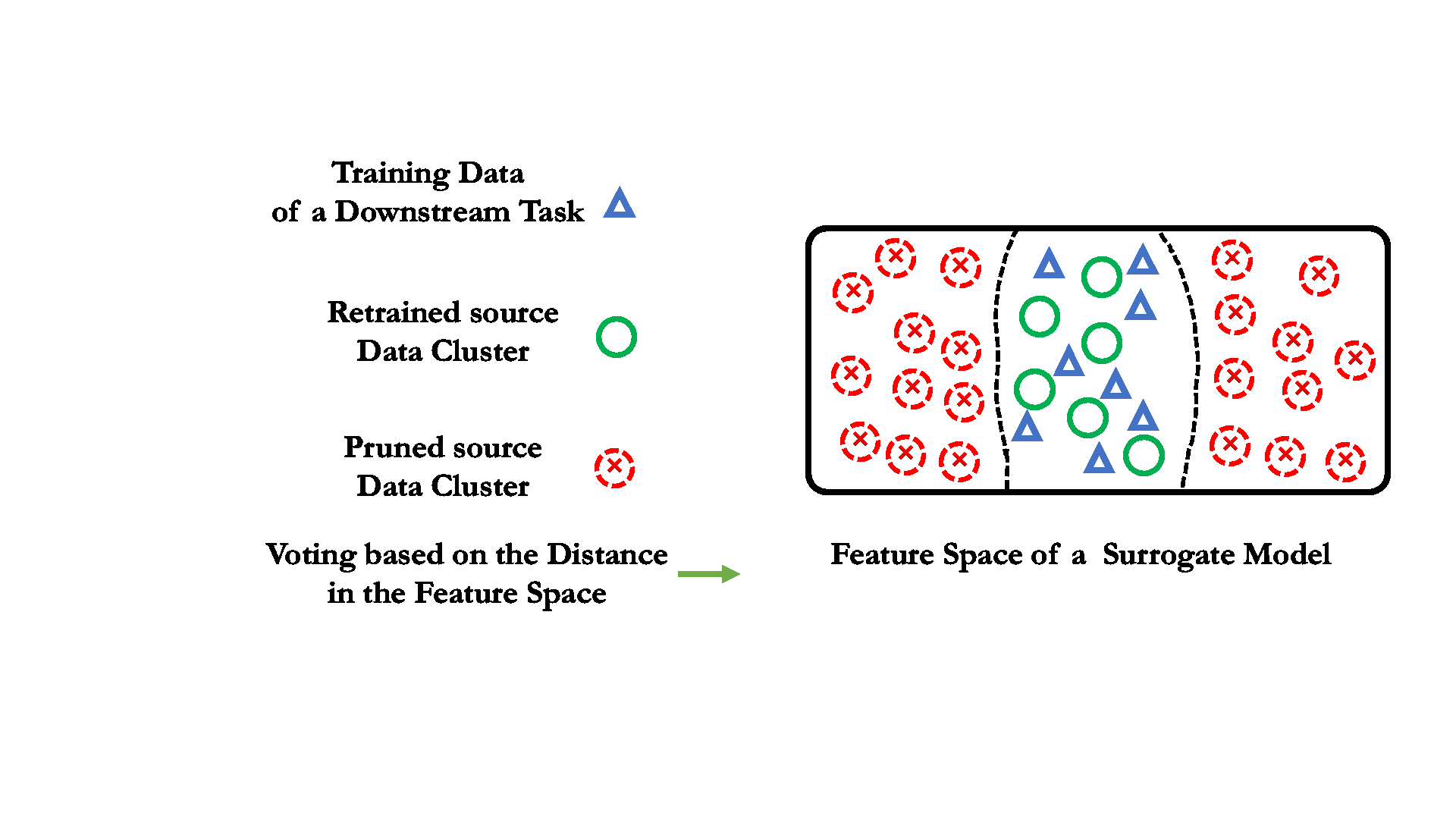
01 Data cluster as pruning unit when labels are unavailable.
One key difference of unsupervised learning from the supervised one lies in the absent data label or class information. We need to cluster the source data first, and the data cluster will serve as the minimum pruning unit, as well as the "voting" candidate.
-
02 Feature mapping through a small surrogate model.
Unlike the supervised pretraining, the small surrogate model can not directly voting through classification. Here, the data relevance is obtained by calculating the feature distance bewteen different data.
For each downstream training data, it votes to the source data cluster with the closest data centroid in the feature space of the pretrained surrogate model.
Experiment Highlights
You can click the title of each experiment to collapse the item.
Please go to Full Experiment Results for more results and demonstrations.
-
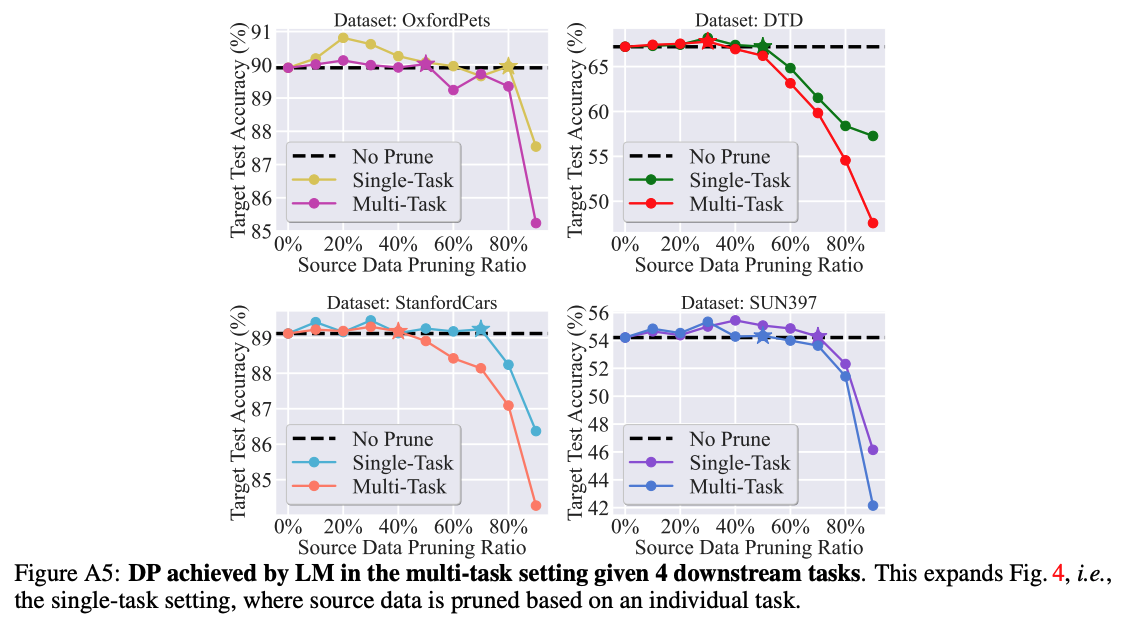
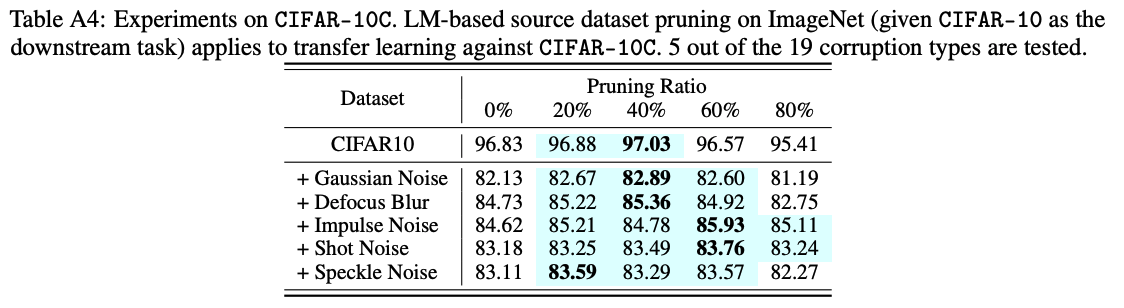
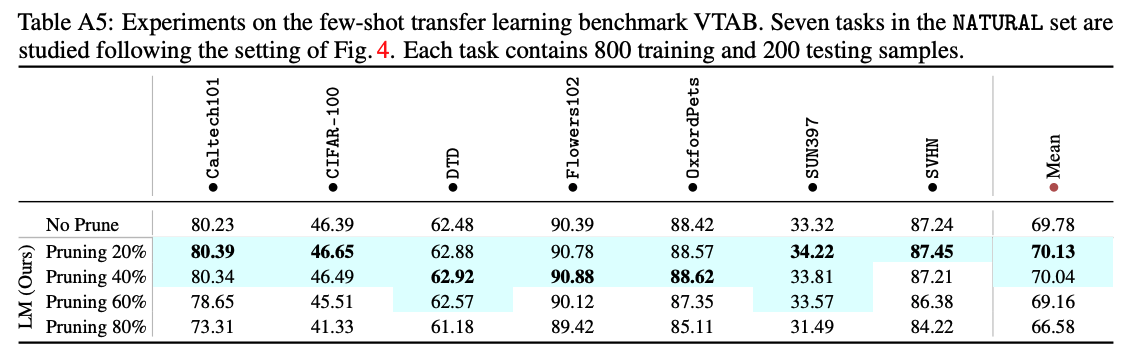
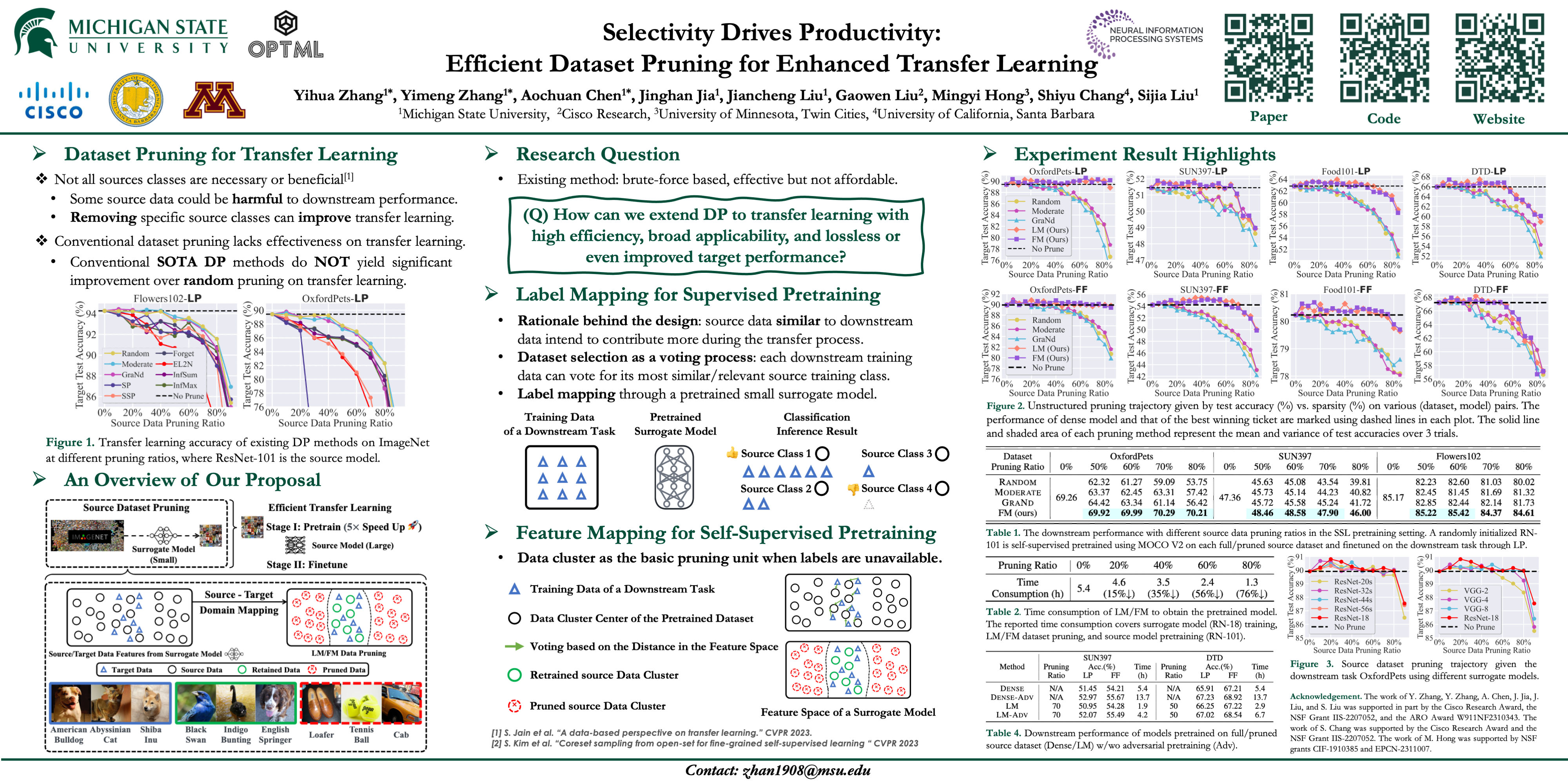
LM/FM prunes the source dataset to large ratios without performance loss in downstream tasks.
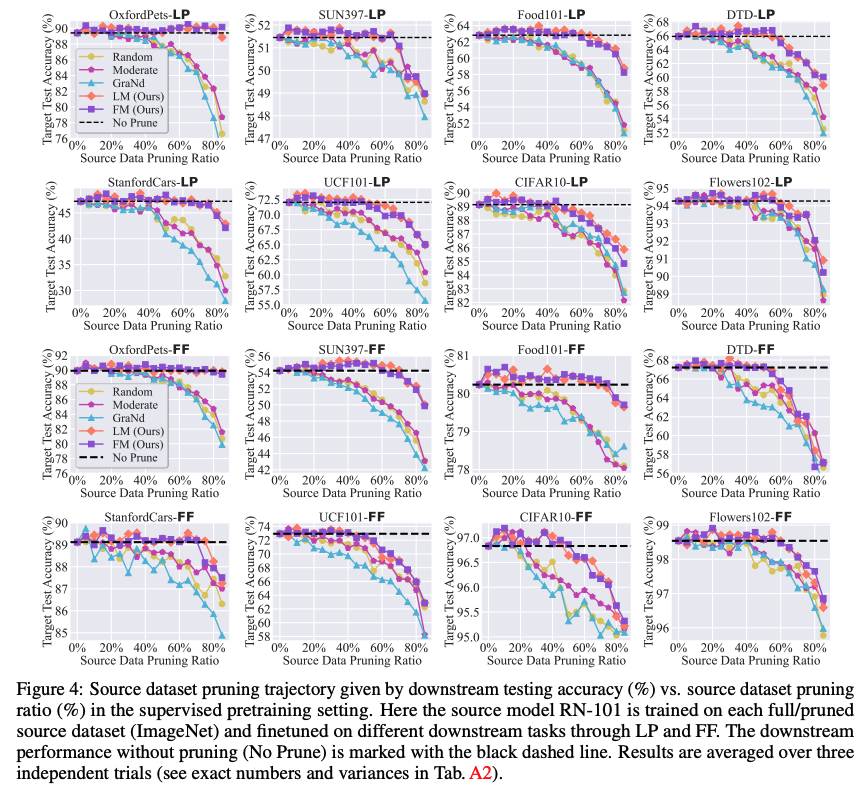
This figure presents the downstream accuracy of transfer learning vs. different pruning ratios. Here DP is performed using the surrogate model (RN-18) on ImageNet for 8 downstream tasks. We also present the downstream performance without pruning the source dataset (No Prune) as a reference for winning subsets. As we can see, both LM and FM significantly outperform the baselines by a substantial margin. This highlights the effectiveness of our proposed methods in achieving substantial dataset pruning without hurting downstream performance.
-
LM/FM improves transfer learning accuracy by identifying ‘winning subsets’
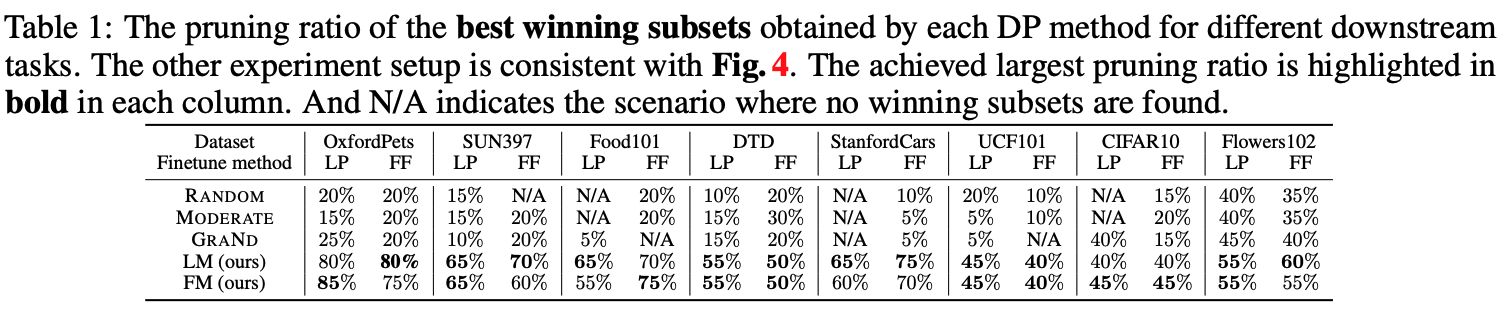
This table provides a summary of the pruning ratios achieved by the best winning subsets identified using different DP methods for all 8 downstream datasets. Both LM and FM methods successfully remove more than 45% of the source classes without downstream performance drop. In contrast, all the baselines experience significant performance degradation when the pruning ratio exceeds 40%.
-
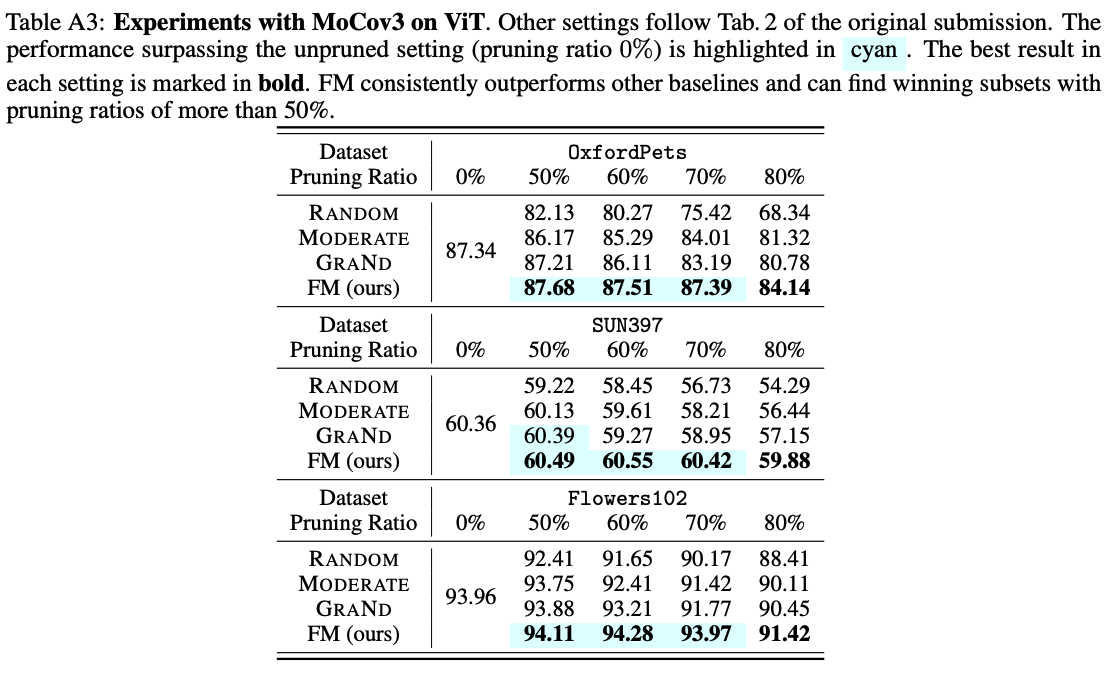
FM demonstrates superior performance in the unsupervised setting.
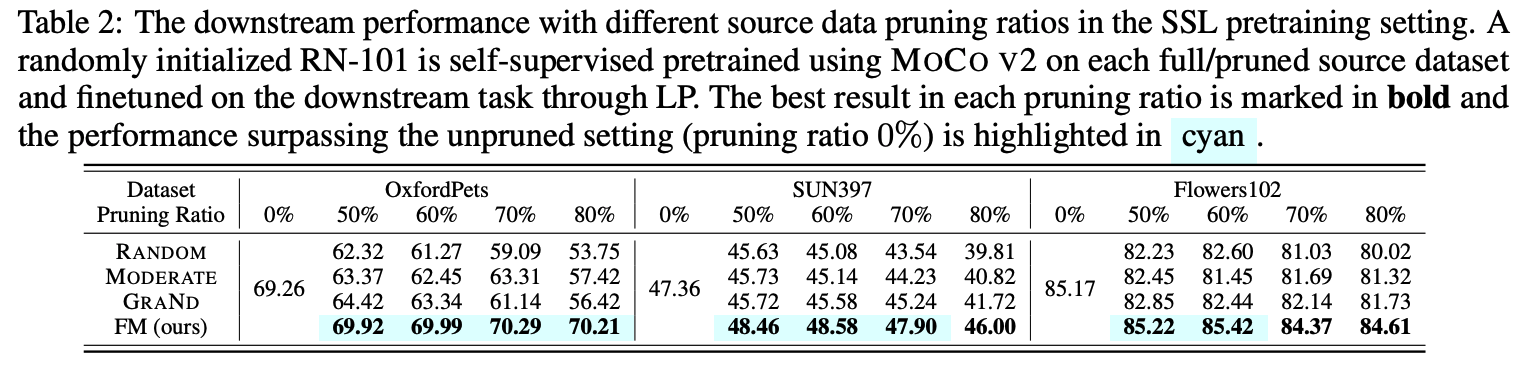
This table highlights the effectiveness of FM-based DP in the self-supervised pretraining setup for three representative downstream tasks. The transfer learning accuracy achieved by using FM consistently outperforms baselines in the self-supervised pretraining paradigm. FM can identify winning subsets for transfer learning even in the challenging regime of large pruning ratios, ranging from 50% to 80%.
-
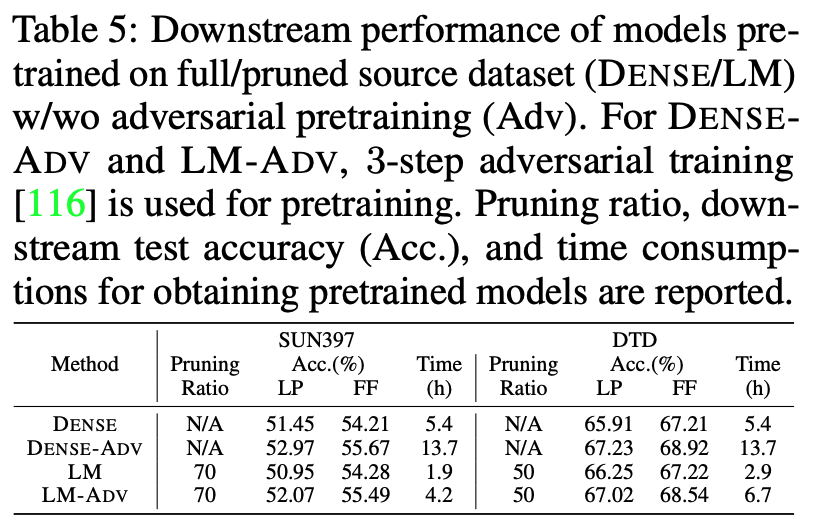
DP enhances the efficiency of source pretraining.

This table displays the computation time required to obtain the pretrained source model using LM at different pruning ratios. The reported time consumption includes the entire pipeline, encompassing surrogate model training (RN18), DP process, and source model training (RN101) on the pruned ImageNet dataset. The runtime cost of the conventional transfer learning on the full ImageNet dataset for RN-101 is also listed as a reference. As we can see, DP enjoys high efficiency merit of source training. Taking the 5.4 hours required for source training on the full ImageNet dataset as a reference, LM-enabled 20% pruned ImageNet achieves a 15% reduction in training time. Moreover, the efficiency advantage increases to 76% when the pruning ratio reaches 80% and these computational benefits do not sacrifice transfer learning accuracy at all.
Full Experiment Results
Please use the tab to select the result of your interest.
Plase click on the image to zoom in for more details and analysis.
- All
- Main
- More
- Ablation
- Visualization
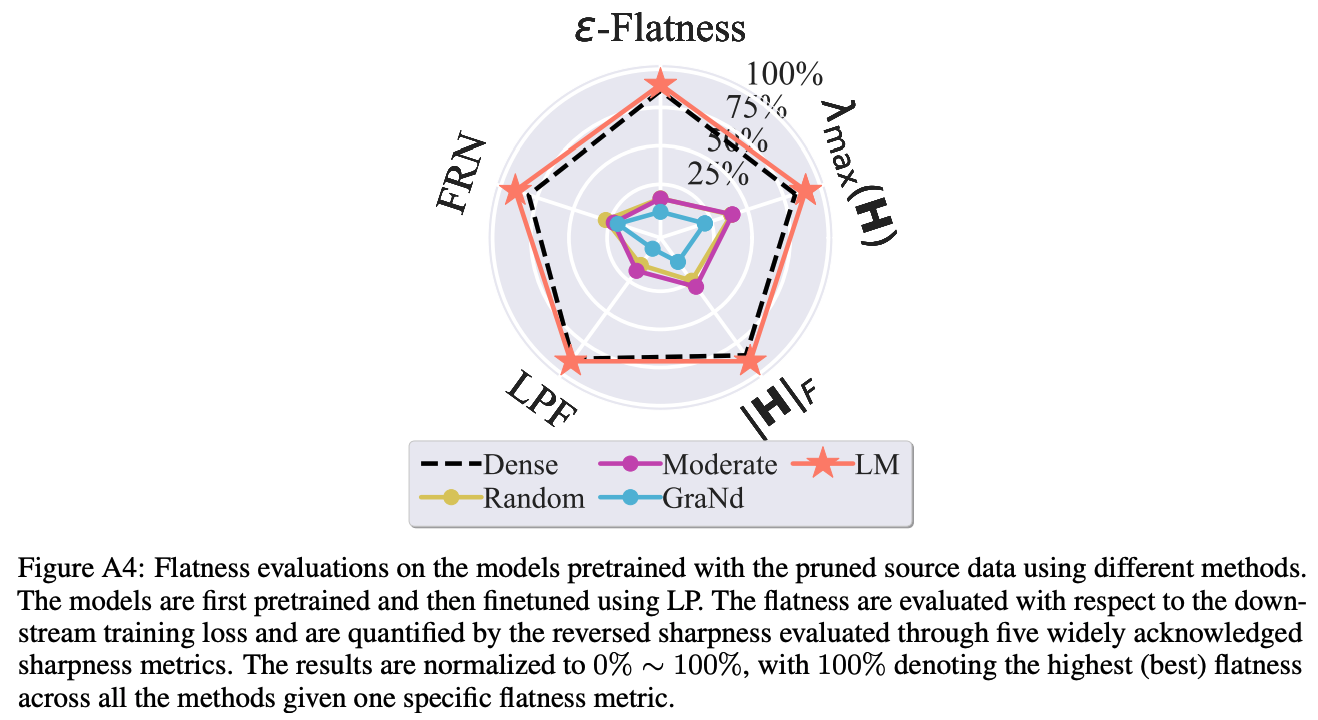
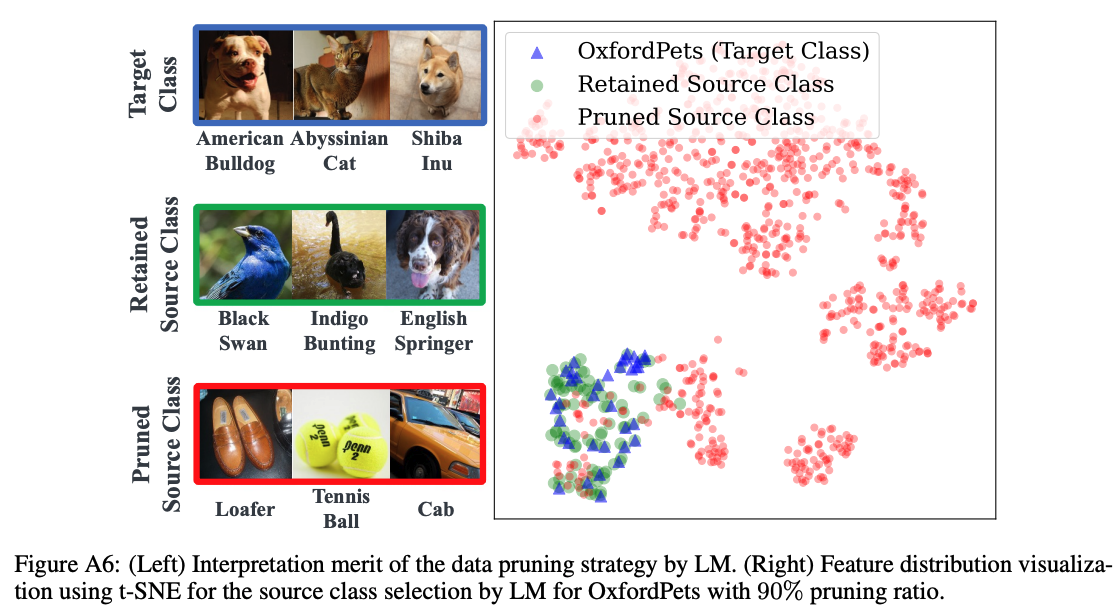



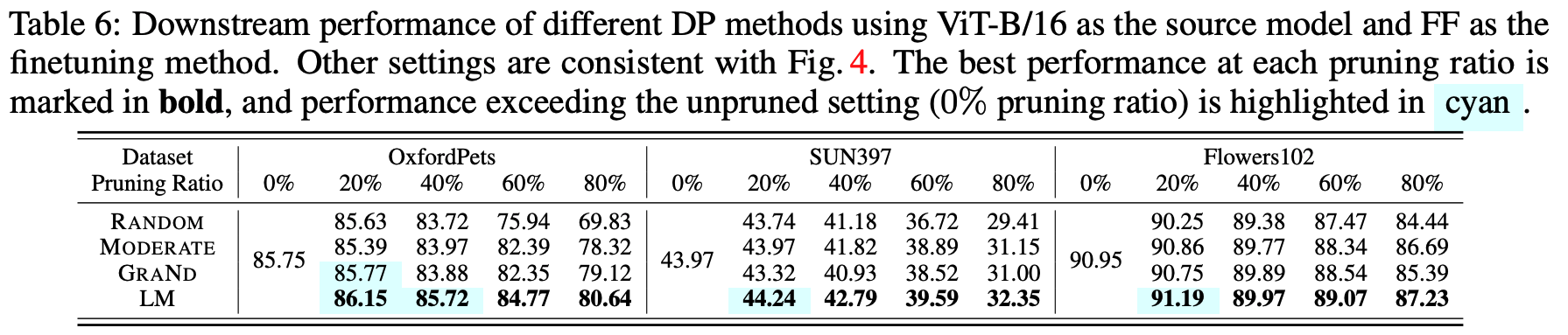


Cite
Please cite our work if you find it helpful!
@inproceedings{zhang2023selectivity,
title={Selectivity Drives Productivity: Efficient Dataset Pruning for Enhanced Transfer Learning},
author={Zhang, Yihua and Zhang, Yimeng and Chen, Aochuan and Jia, Jinghan and Liu, Jiancheng and Liu, Gaowen and Hong, Mingyi and Chang, Shiyu and Liu, Sijia},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023}
}









{kind=link}